Mastering Data Formats in Pandas: Transitioning with Ease
Written on
Understanding Data Formats
Data scientists often face a universal challenge: data is rarely in the perfect format. You may receive organized spreadsheets or logically structured tables, but there’s always a need for some degree of preprocessing before you can analyze the data effectively.
Consequently, mastering the ability to convert between various data formats is essential. Sometimes it’s about making the data more interpretable, while other times, specific software or models require data in a particular structure. Regardless of the reason, this skill is invaluable.
This article delves into two prevalent data formats: long-form and wide-form data. These are foundational concepts in data science, and becoming acquainted with them is crucial. We'll examine examples to illustrate the differences between these formats and demonstrate how to switch between them using Python, particularly with the Pandas library.
Let’s dive in!
Long-Form vs. Wide-Form Data
To start, let’s define these two formats clearly:
- Wide-form data is structured such that there’s a single row for each unique value of your independent variable, with all dependent variables displayed as column headers. Thus, every row features a distinct label for the independent variable.
- Long-form data contains one row per observation, with each dependent variable represented across multiple rows. This results in repeated values for the independent variable within the dataset.
Now, what does this look like in practice? Consider a dataset of students with their scores for a midterm exam, final exam, and class project. In wide format, the data appears as follows:
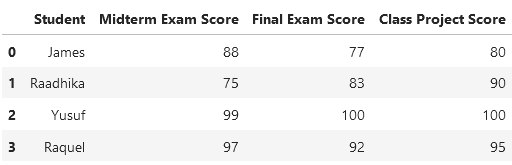
In this representation, each student is an independent variable, while the exam and project scores are dependent variables, with unique values for each student.
Now, let’s view the same data in long format:
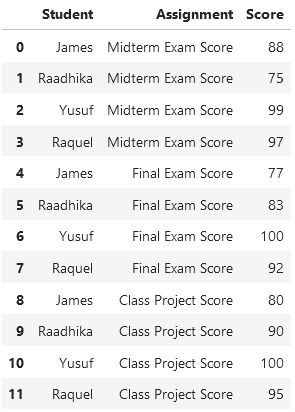
In this instance, every score corresponds to a separate observation, with each row representing an individual score. Here, the independent variable (Student) appears multiple times, as expected in long-form data.
Before we explore why understanding these formats is important, let’s examine how to utilize Pandas for converting between these structures.
Transforming Wide-Form Data to Long-Form: The Melt Function
Let’s revisit the wide-form data example, now named student_data:
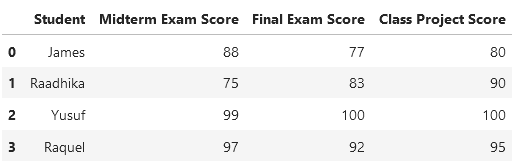
To convert this dataset into long-form, we can use the following command:
student_data.melt('Student', var_name='Assignment', value_name='Score')
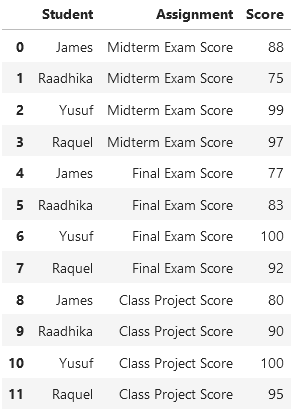
Here’s a breakdown of the process:
- The melt function is specifically designed to reshape wide-form data into long-form.
- The var_name parameter allows you to designate the name of the second column (which will hold the dependent variables).
- The value_name parameter names the third column, containing the observed values (in this case, scores).
Now that we have our long-form data, what if we need to revert to wide format?
Reverting Long-Form Data to Wide-Form: The Pivot Function
We start with the long-form dataset, referred to as student_data_long. To revert to the original wide format, use the following command:
student_data_long.pivot(index='Student', columns='Assignment', values='Score')
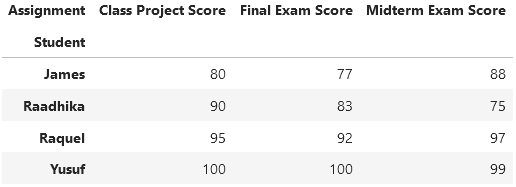
This transformation yields the same data as we began with, albeit with slightly different labels (the pivot function summarizes with the column label 'Assignment').
Here’s how it works:
- The pivot function is used for converting long-form data to wide-form, but it also offers a range of additional functionalities.
- The index parameter selects the column whose values will serve as unique rows (the independent variable).
- The columns parameter determines which column’s unique values will become the headers in the wide format.
- The values parameter specifies which column will populate the actual data entries in this new format.
And that’s all there is to it!
Why Is This Knowledge Valuable?
While the distinctions between these formats may seem trivial at first glance, they are profoundly beneficial to your data manipulation skills. Often, the format of your data can dramatically affect your workflow.
For instance, in my own experience with data visualization in Python using Altair, I discovered an unexpected hurdle: most datasets come in wide format, but Altair functions more smoothly with long-form data. After considerable effort troubleshooting a specific visualization, I found that simply converting to long format would solve my problem.
You may not specifically work with visualizations, but if you're engaging with data, understanding how to manipulate it is essential. This knowledge adds another useful tool to your skill set.
Best of luck in your data science journey!
This tutorial covers how to read and write data using Pandas, including various formats like Excel, JSON, and SQL.
This video demonstrates reading files in Pandas, providing practical insights into managing data effectively.