Understanding Natural Language Processing: A Beginner's Guide
Written on
Chapter 1: Introduction to AI and NLP
Artificial Intelligence (AI) has become a hot topic in 2023, especially following the introduction of ChatGPT in late 2022, a prime example of generative AI. In essence, AI refers to technologies that empower computers to execute complex tasks such as visual perception, understanding and translating language—both spoken and written, analyzing data, and providing recommendations.
As someone without a technical background, I have always been eager to gain a deeper understanding of fundamental technical concepts. Even if I can’t code at a high level, having a grasp of workflows and terminology enables me to communicate more effectively with engineers and other technical professionals. This article aims to clarify these concepts for those who might share similar experiences.
In this series of articles, I will delve into Natural Language Processing (NLP) and its related topics.
Section 1.1: What is Natural Language Processing?
At its core, Natural Language Processing is a significant field within AI focused on facilitating computers’ understanding of human language, both in writing and speech. This is achieved by developing algorithms and models that allow machines to interact with human languages.
For instance, virtual assistants like Amazon's Alexa and Apple’s Siri utilize NLP to enhance user experience. Other applications include automated customer service replies and chatbots that help users before connecting them to human representatives. Common features like Google Search's autofill also exemplify the use of NLP.
Video Title: NLP Demystified 1: Introduction - YouTube
This video provides an introductory overview of Natural Language Processing, explaining its significance and foundational concepts in a clear and approachable manner.
Section 1.2: Steps in Natural Language Processing
NLP models function by uncovering meaningful relationships within language components; in the context of text data, this pertains to words and sentences. For machines to analyze text data, the raw text must first undergo a process known as "Data Preprocessing."
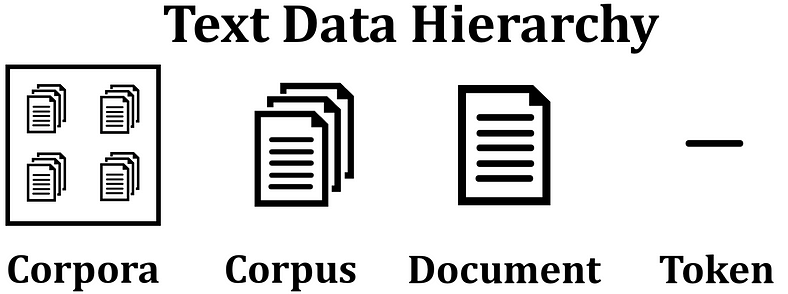
Before we explore the specific steps involved in data preprocessing, let's become familiar with the hierarchy of text data:
- Token: The smallest unit, representing an individual word or sometimes a sentence.
- Document: A collection of tokens, encompassing a paragraph or a chapter.
- Corpus: A set of documents, such as an article or a book.
- Corpora: A collection of corpuses, representing multiple articles or books.
With this basic hierarchy in mind, we can appreciate the process of data preprocessing.
Data Preprocessing involves transforming text into a simplified format that models can process. Various techniques are employed, typically in the following order:
- Text Cleaning: This step eliminates irrelevant characters (punctuation, tags, etc.) that do not contribute to the sentence's meaning, often referred to as noise.
- Sentence Segmentation: This involves breaking lengthy texts into coherent sentence units. This can be challenging, particularly in languages like English, where periods may signify both sentence endings and abbreviations, and in Chinese, which lacks spacing.
- Lowercase Conversion: As the name suggests, this technique changes all text to lowercase.
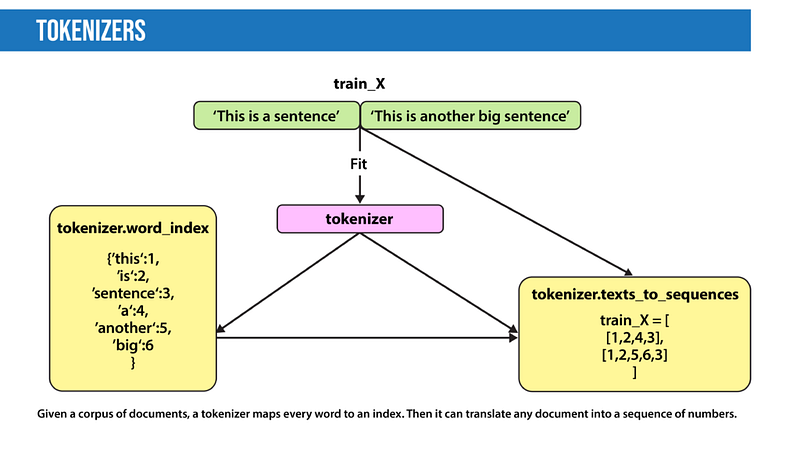
- Tokenization: This breaks down text into individual words, or tokens, which are the smallest units in the data structure. The outcome usually includes a word index and a tokenized text, representing words as numerical values.
Once tokenization is complete, advanced techniques can be applied to classify tokens:
- Part of Speech (POS) Tagging: This identifies the grammatical category (noun, verb, adjective, etc.) of each token. POS tagging is crucial for dealing with words that may belong to multiple categories, such as “google.”
- Named Entity Recognition (NER): This involves identifying specific tokens as entities (e.g., names of people, locations, or organizations). NER is most effective when applied after POS tagging, focusing on tokens tagged as nouns.

Other preprocessing techniques include:
- Stop Words Removal: This eliminates common words (like "the," "is," and "a") that add little meaning to the text.
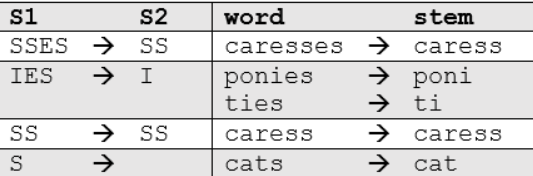
- Stemming: This process reduces words to their root form by trimming prefixes or suffixes, following specific rules.
- Lemmatization: Similar to stemming but more accurate, it finds the base form of words using morphological analysis and a dictionary.
- N-gram: This technique examines combinations of words, useful for contexts where the sequence of words matters.
Following these preprocessing techniques, the text data must be converted into numerical representations through a process known as "text data vectorization." This is a complex topic that warrants further discussion in a future article. Stay tuned!
Video Title: Demystifying Natural Language Processing: A Beginner's Guide - YouTube
This video serves as a beginner's introduction to Natural Language Processing, breaking down its concepts and applications in an easily digestible format.