Efficient Model Deployment with BentoML and MLFlow in Minutes
Written on
Introduction to Fast Model Deployment
Creating machine learning models is a time-intensive task. According to Algorithimia’s 2021 report on Enterprise Trends in Machine Learning, 64% of businesses take a minimum of one month to deploy their models. This lengthy process can be reduced by at least half, allowing data scientists to focus on crafting cleaner and more effective features, ultimately leading to improved model accuracy.
However, selecting the right tools for deployment can be a daunting challenge due to the vast array of available options. Thankfully, using MLFlow and BentoML can simplify the MLOps landscape considerably.
MLFlow is particularly effective for experimenting with various models and fine-tuning hyperparameters, which helps in identifying the optimal model. Integrating BentoML facilitates the serving and deployment of models in a production environment by:
- Importing the best model from the MLFlow registry.
- Constructing an API service with BentoML.
- Creating and containerizing Bento for deployment.
The addition of BentoML to the MLFlow pipeline provides a comprehensive historical view of your training and deployment activities. As the model trains, MLFlow captures the runs and their parameters in its registry, which is designed for model comparison and selection throughout the experimentation process. BentoML retains this training context in its own registry for future reference, managing deployable artifacts (Bentos) and streamlining the model inference workflow.
MLFlow operates seamlessly on a BentoML runner, allowing users to leverage features such as input validation, adaptive batching, and parallel processing. The BentoML registry promotes reproducibility across development, testing, and production stages, enabling visualization of the training and deployment lifecycle.
In this guide, you will discover how to:
- Utilize MLFlow for experiments and model selection.
- Deploy the best model swiftly using BentoML.
Setting Up MLFlow and BentoML
MLFlow is an open-source framework that manages the complete machine learning lifecycle by logging parameters, code versions, metrics, and output files. The beauty of this framework is that it requires just one additional line of code to ensure the model's accuracy.
To install MLFlow with the specific version used in this guide, run:
pip install mlflow==1.26.1
To launch a testable MLFlow UI, execute:
mlflow ui
BentoML is also an open-source framework, specifically for Python, enabling rapid deployment and serving of machine learning models at scale. Install it using:
pip install bentoml==1.0.0
To illustrate how BentoML and MLFlow function together, we will train a model that predicts housing prices based on various features. The complete code can be found on GitHub.
Preparing Data for Training
First, download the "House Sales in King County, USA" dataset from Kaggle. Fortunately, most of the dataset is clean, but we must handle null values when predictions are made. During training, we utilize df.dropna(). To ensure consistent preprocessing during both training and prediction phases, this step will need to be encapsulated in a callable function.
There are two methods to eliminate null values. The first involves incorporating df.dropna() directly within the service endpoint, which is straightforward as it's not resource-intensive. Alternatively, the second method allows for separate scaling of transformations and the model, which is beneficial when managing heavier transformations. This can be achieved by adding another Runnable with the @bentoml.Runnable.method decorator.
Hyperparameter Tuning with MLFlow
Once the MLFlow UI is set up, we can train the model and optimize its hyperparameters. To log each experiment, simply add the following line before initiating any experiments:
mlflow.sklearn.autolog()
Every MLFlow run will automatically log data and store it in the local metrics repository, which the UI can access.
Now, we will predict housing prices using features such as:
- Number of bedrooms
- Number of bathrooms
- Living room and lot area
- Number of floors
- Waterfront view
- View quality index (0 to 4)
- House condition
- Construction and design grade
- Above and below-ground housing space area
- Year built and renovated
- Location (zipcode, latitude, longitude)
- Square footage of living space and lot for the nearest 15 neighbors
For full column explanations, refer to the Kaggle discussion.
We will train a RandomForestRegressor model using the following parameter grid:
{
'n_estimators': [100, 200],
'max_features': [1.0],
'max_depth': [4, 6, 8],
'criterion': ['squared_error']
}
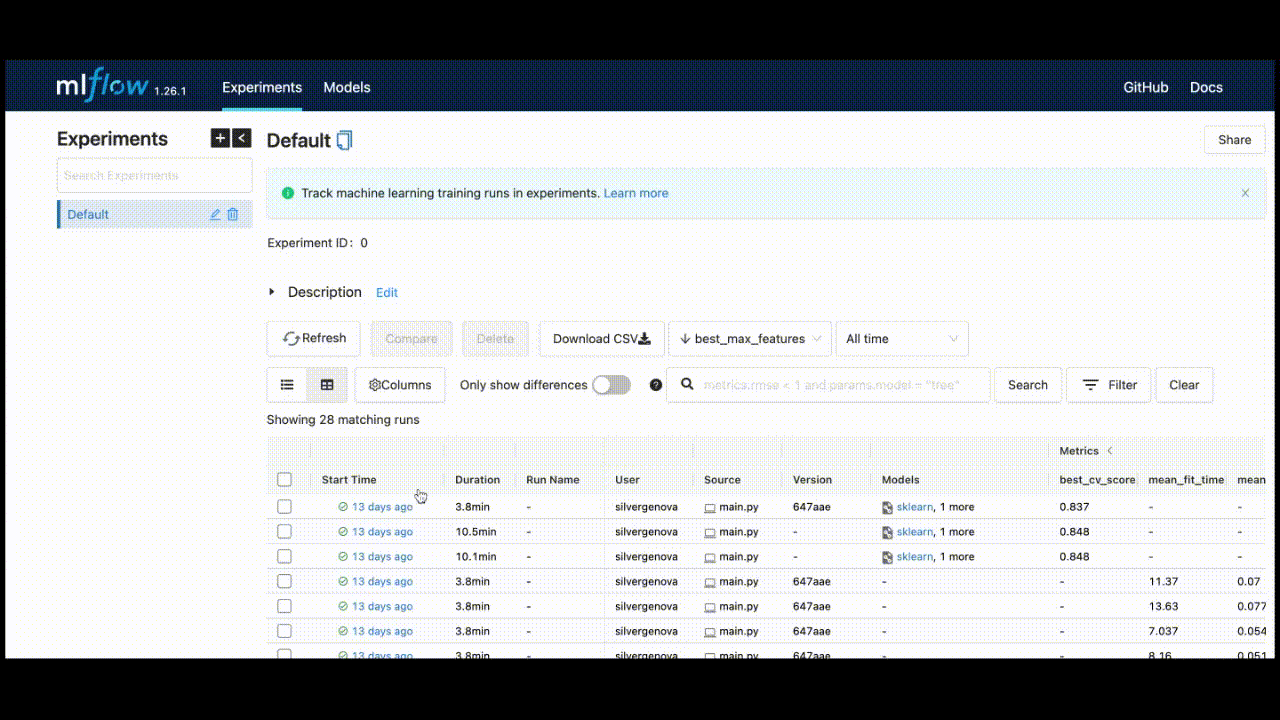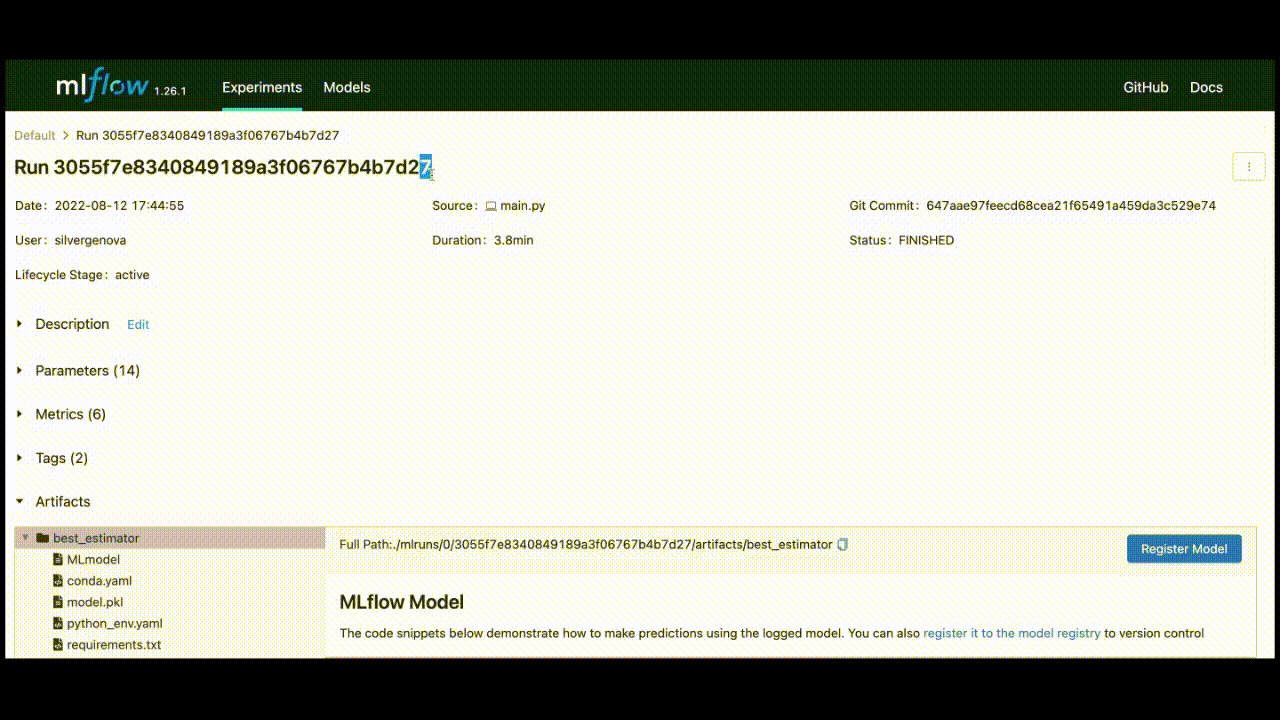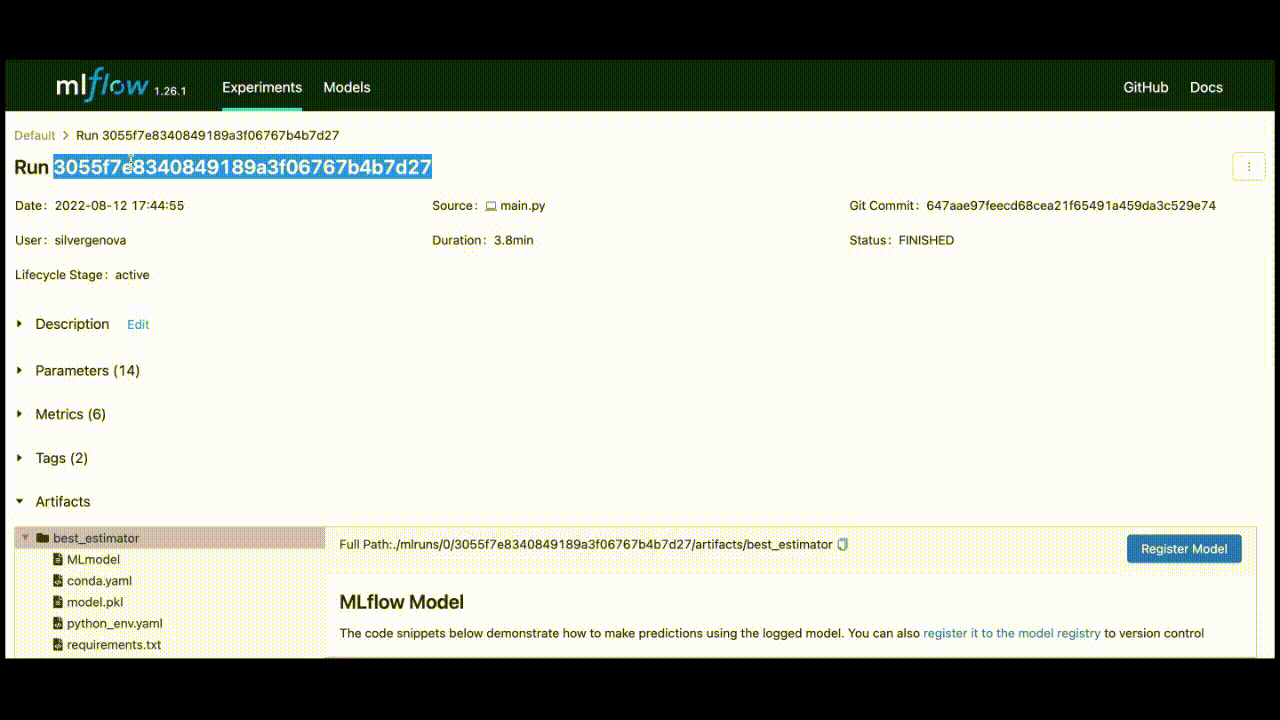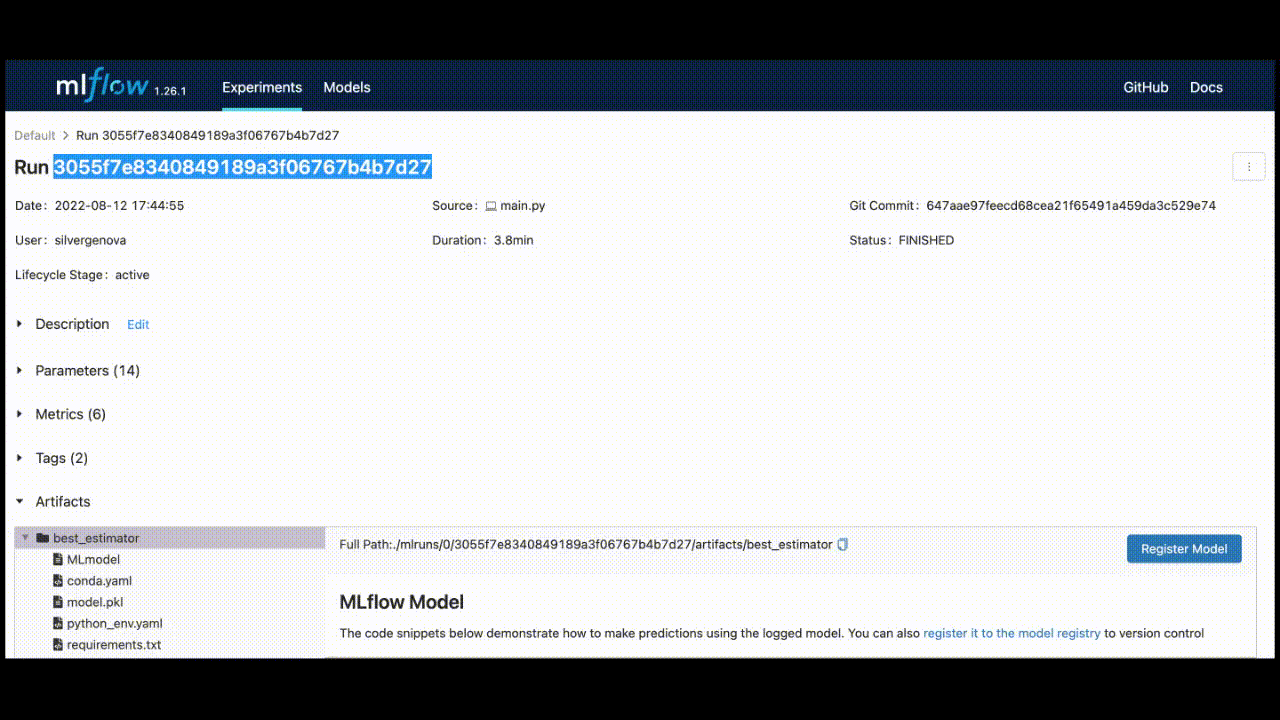
This will help us identify the best model with the lowest squared error. After completing all experiments, the MLFlow UI will compile the metrics from the local repository and display them neatly at http://127.0.0.1:5000/.
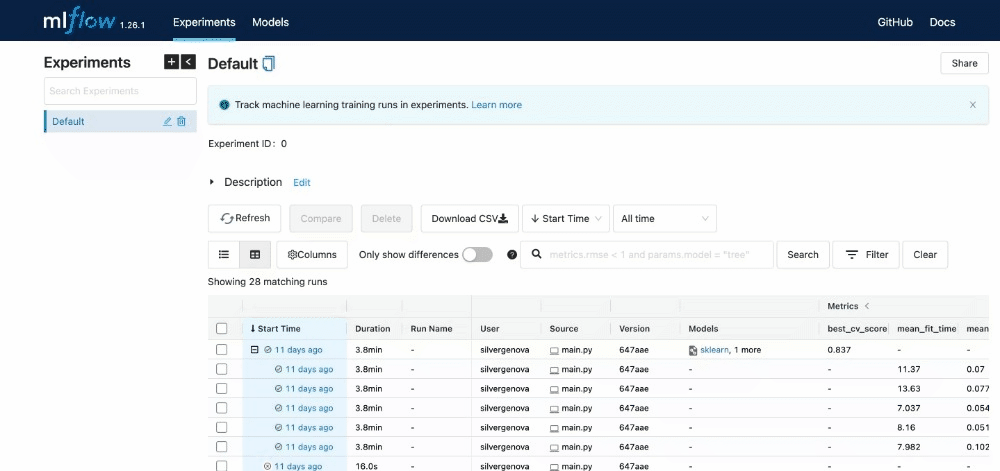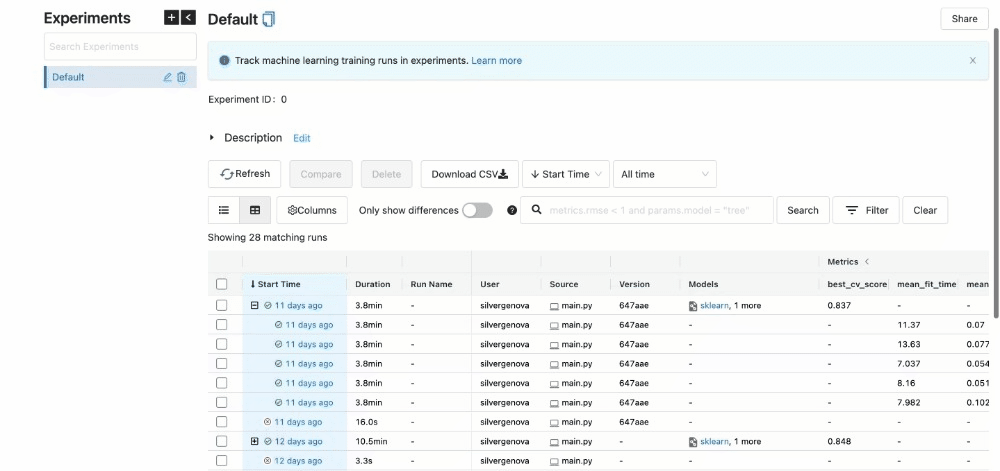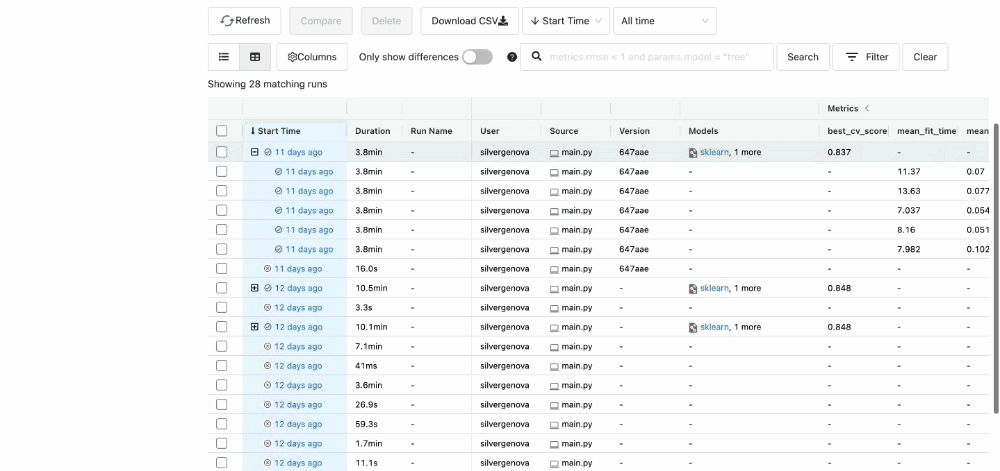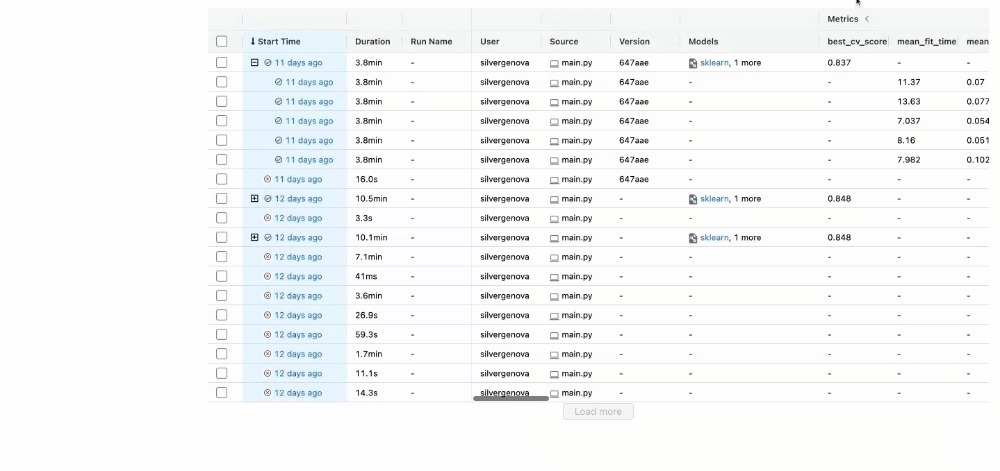
You can view the extent of the characteristics listed in the UI.
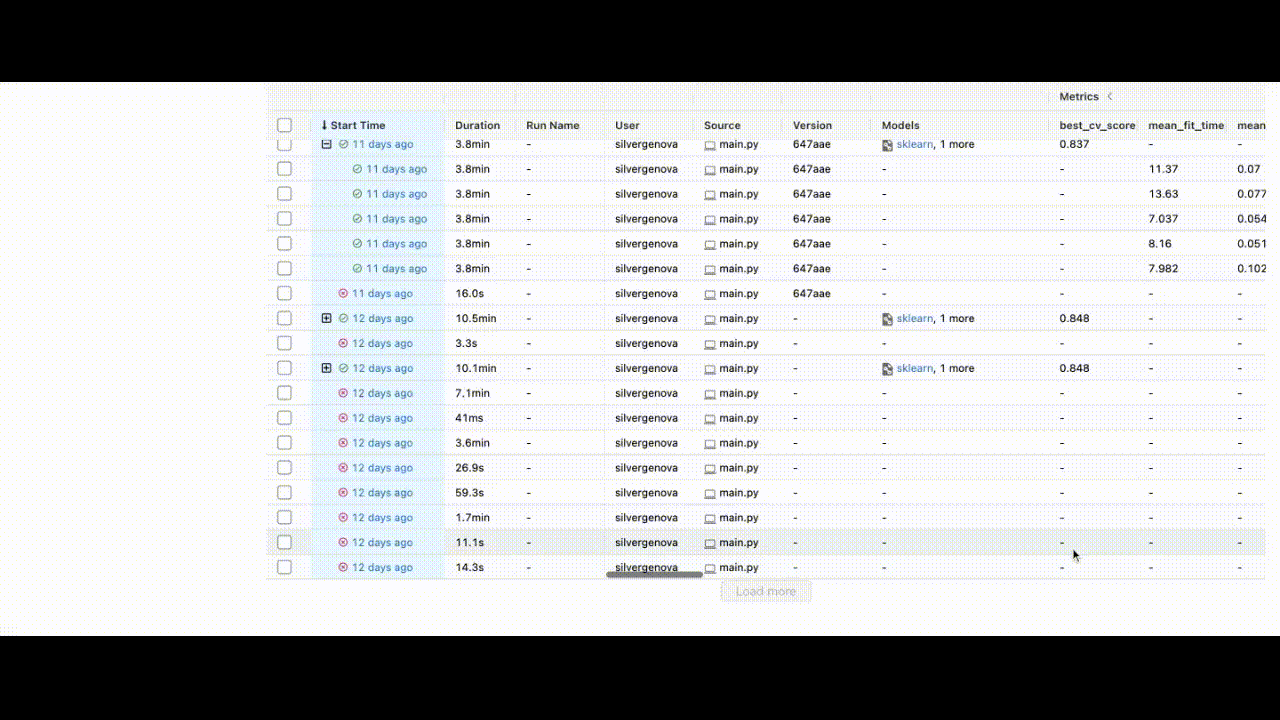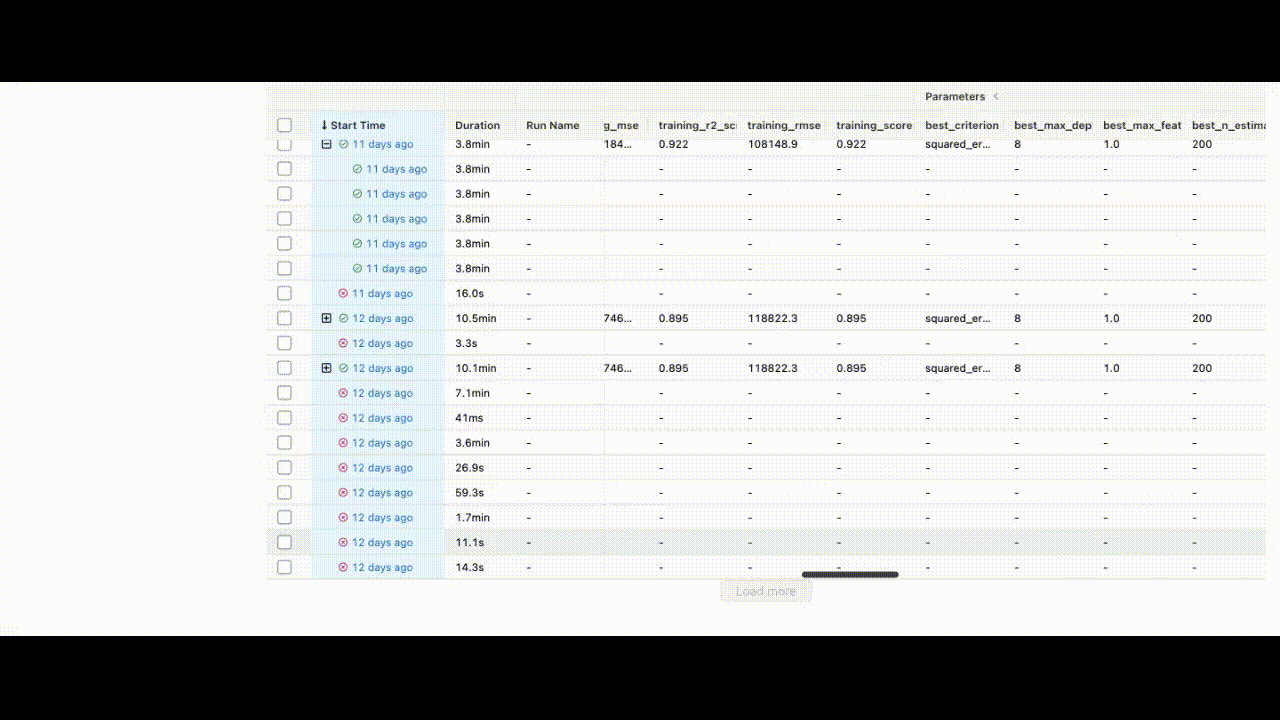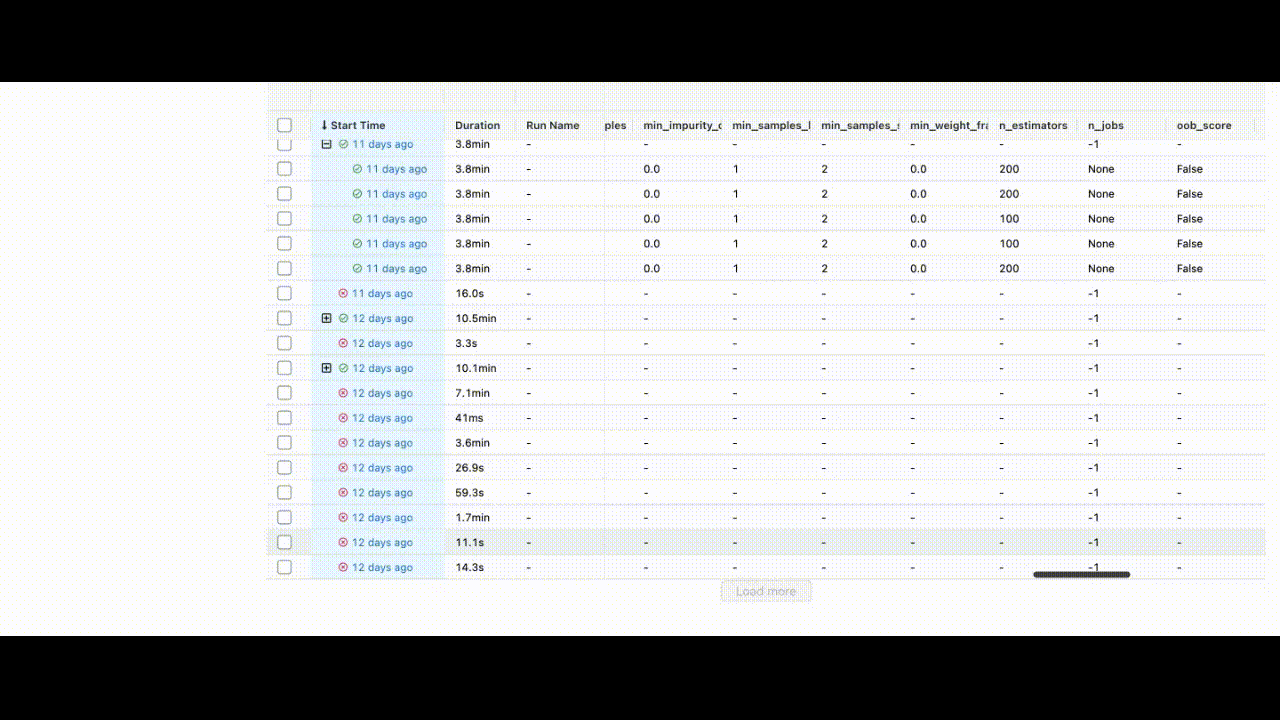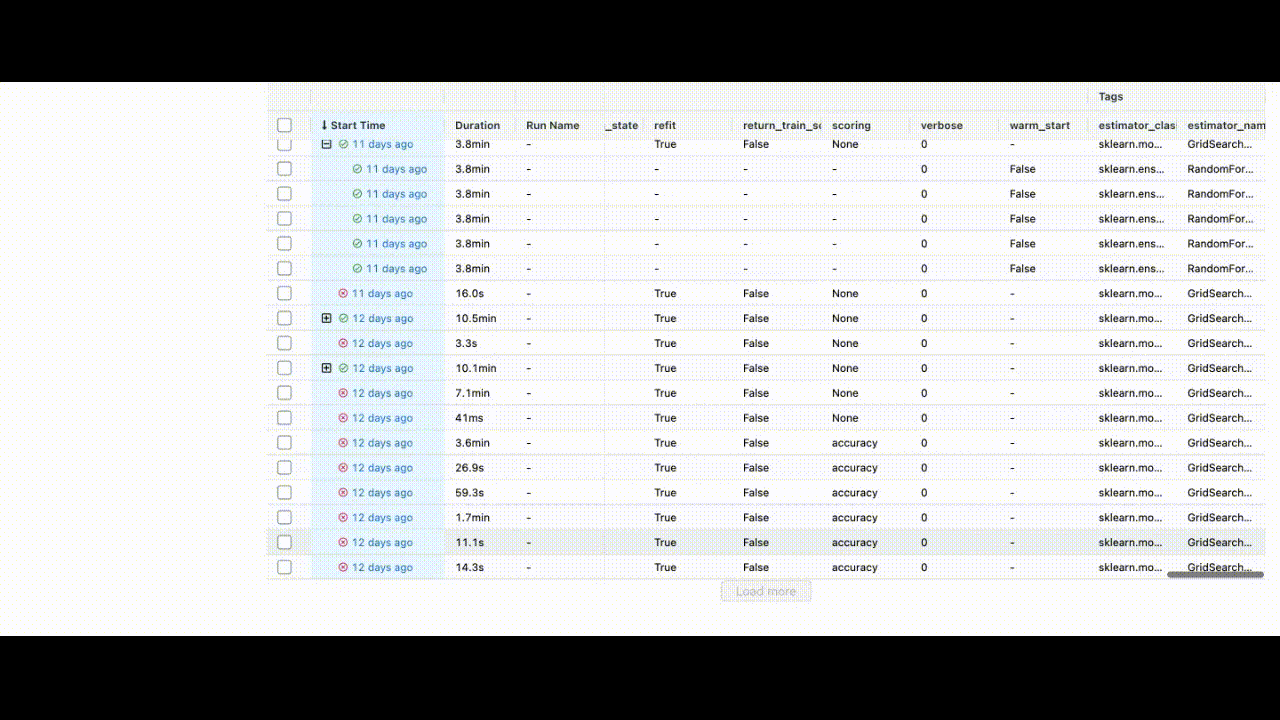
After training the model, we can save the identifier of the best model to the BentoML repository using:
bento_model = bentoml.mlflow.import_model("sklearn_house_data", model_uri)
The model_uri consists of a run_id, which uniquely identifies the MLFlow job run, and the artifact_path.
You can retrieve the run_id by saving the last run_id, or it can be found in the top left corner of the UI.
Once you have that ID and specify “best_estimator” for the artifact_path, your model_uri will be:
model_uri = "runs:/3055f7e8340849189a3f06767b4b7d27/best_estimator"
This is the final piece required to save the model on the BentoML server:
bento_model = bentoml.mlflow.import_model("sklearn_house_data", model_uri,
labels=run.data.tags,metadata={
"metrics": run.data.metrics,
"params": run.data.params,
})
Notice that MLFlow data has been incorporated into BentoML for visibility in the BentoML registry. The full code is available on GitHub.
Serving Predictions with BentoML
Predictions can be made either from a file or by sending data directly. Testing with a file path is convenient. The decorator @service.api marks the predict function as an API, with the input being a file path string, and the output returning predictions in JSON format. The File class ensures that the input, file_path, is indeed a string.
In the Swagger UI, you can see an example value.
Now, I will implement a sample value of data/test/X_test.csv, which yields a remarkable list of predictions.

However, sending a file path is impractical for production environments. The @service.api decorator indicates that the predict function is an API, with the input being a list of data and the output providing predictions in JSON format.
In the Swagger UI, let's submit the following example to the API:
[[4,2.25,2070,8893,2,0,0,4,8,2070,0,1986,0,98058,47.4388,-122.162,2390.0,7700],
[2,2.25,2000,8893,2,0,0,4,8,2030,0,1986,0,98058,43.4388,-122.162,2390.0,7700]]

And the predictions are here! The output is:
{
"prices": [
423734.2195988144,
307359.1184546088
]
}
The complete code is also accessible on GitHub.
Conclusion
In this article, we successfully identified the best model for predicting house prices using MLFlow, which was then deployed in mere seconds with BentoML. The integration of BentoML and MLFlow accelerates the deployment of machine learning models, enhancing the efficiency of data teams.
Chapter on Deploy and Scale Models with BentoML
In this chapter, we will explore the video "Deploy and Scale Models with BentoML" to further understand how to implement these concepts effectively.
The video demonstrates practical applications of BentoML in deploying and scaling models.
Chapter on MLflow Crash Course
Additionally, we will review the "MLflow Crash Course - Model Registry and Model Deployment" video, which provides insights into model management and deployment strategies.
This resource is vital for understanding MLflow's capabilities in model registry and deployment.